SyncDPO
Improving Temporal Alignment in Video-Audio Joint Generation via Preference Optimization

Abstract
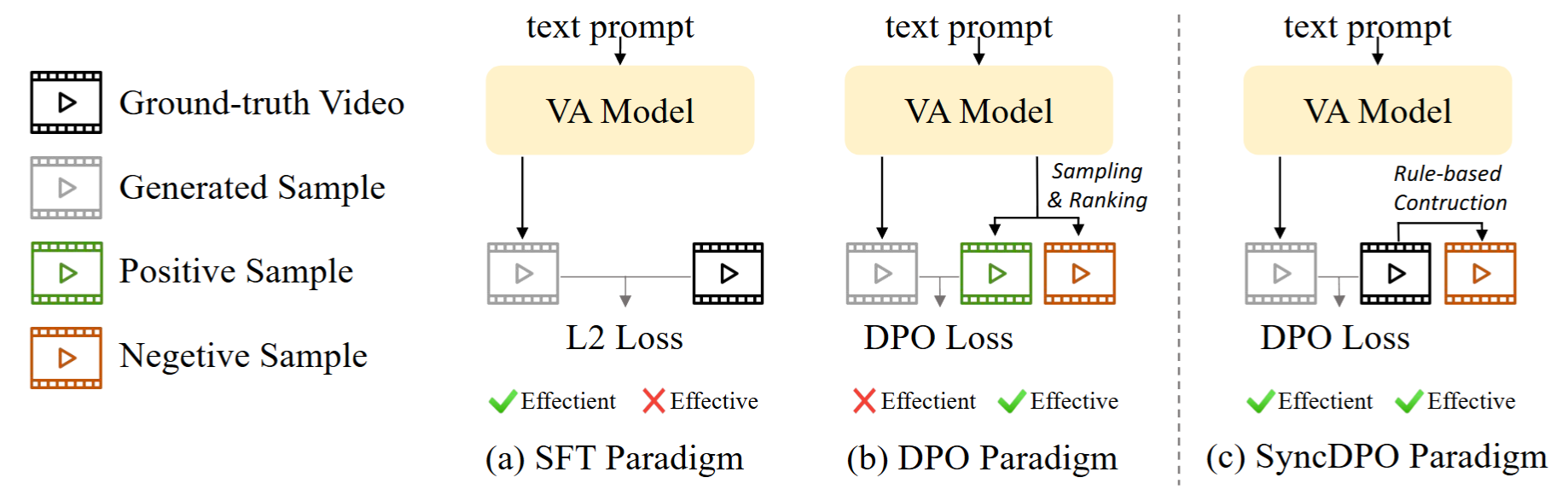
Recent advancements in video-audio (V-A) joint generation have achieved remarkable success in semantic correspondence. However, achieving precise temporal synchronization, which requires fine-grained alignment between audio events and their visual triggers, remains a formidable challenge. Despite recent progress, post-training for audio-visual joint generation remains relatively underexplored and is largely dominated by Supervised Fine-Tuning (SFT). However, the commonly used Mean Squared Error (MSE) loss provides insufficient penalties for subtle temporal misalignments. Direct Preference Optimization (DPO) provides a stronger alternative by introducing explicit contrastive supervision between well-aligned audio-visual samples and misaligned counterparts. In this paper we propose a post-training framework SyncDPO, leveraging DPO to improve the temporal sensitivity of V-A joint generative models. Existing DPO pipelines typically depend on costly sampling-and-ranking procedures to construct preference pairs, resulting in substantial computational overhead. To improve efficiency, we introduce a suite of on-the-fly, rule-based negative construction strategies that distort temporal structures without incurring additional annotation or sampling overhead. We demonstrate that the temporal alignment capability can be effectively reinforced by providing explicit negative supervision through temporally distorted V-A pairs. To further enhance the performance, we implement a curriculum learning strategy that progressively increases the difficulty of negative samples, transitioning from coarse misalignment to subtle inconsistencies. Extensive objective and subjective experiments across four diverse benchmarks, ranging from ambient sound to human speech videos, demonstrate that SyncDPO significantly outperforms other methods in improving model's temporal alignment capability. It also demonstrates superior generalization on out-of-distribution benchmark by capturing intrinsic motion-sound dynamics. Code and models will be made publicly available soon.
Please visit the Samples page for qualitative comparisons between Base (No Tune), SFT, and SyncDPO.